SCAPE clustering
SCAPE (Scaling Clusters of Actors on Processing Elements) addresses the challenges of scheduling massively parallel applications by automatically adjusting the granularity of applications to match the target architecture. It reduces graph complexity, improves scheduling efficiency, and aligns parallelism with multi-core CPU capabilities through an agglomerative clustering approach.
The following topics are covered in this tutorial:
- Granularity Adjustment
- Reduced Complexity
- Improved Parallelism
Prerequisite:
- Install PREESM see getting PREESM
- Tutorial Introduction
- Parallelize an Application on a Multicore CPU
Tutorial created the 14.11.2023 by O. Renaud
Principle
Dataflow agglomerative clustering
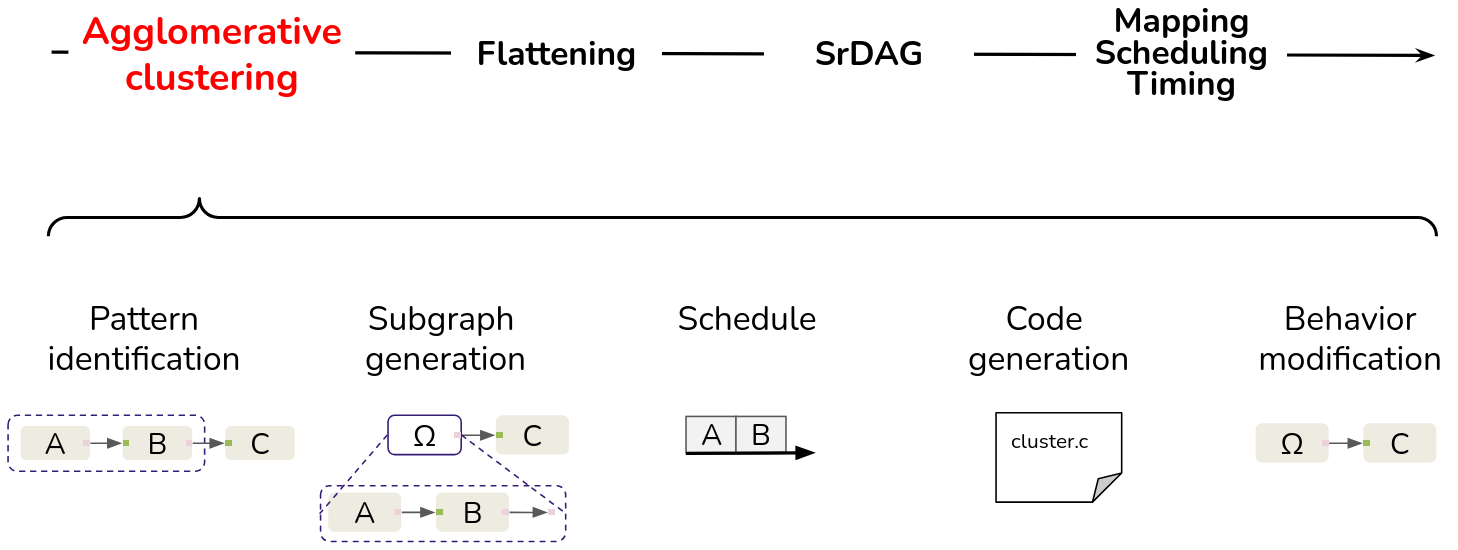
The following steps outline the SCAPE clustering process:
- Identification of Patterns: Particular patterns of actors are identified.
- Subgraph generation: These identified actors are grouped to form subgraphs.
- Schedule: The scheduling of the newly created subgraph is computed with the APGAN scheduler.
- Code Generation: Subgraph behavior is translated into C code.
- Graph Transformation: The hierarchical actor’s behavior is replaced by the generated code to reduce graph size and improve subsequent scheduling and placement processes.
The clustering process improves scheduling performance and reduces execution time by tailoring the graph size and its parallelism to the target architecture.
The 3 SCAPE modes
SCAPE is composed of 3 clustering method each extending the previous one.
Data Parallelism Adjustment
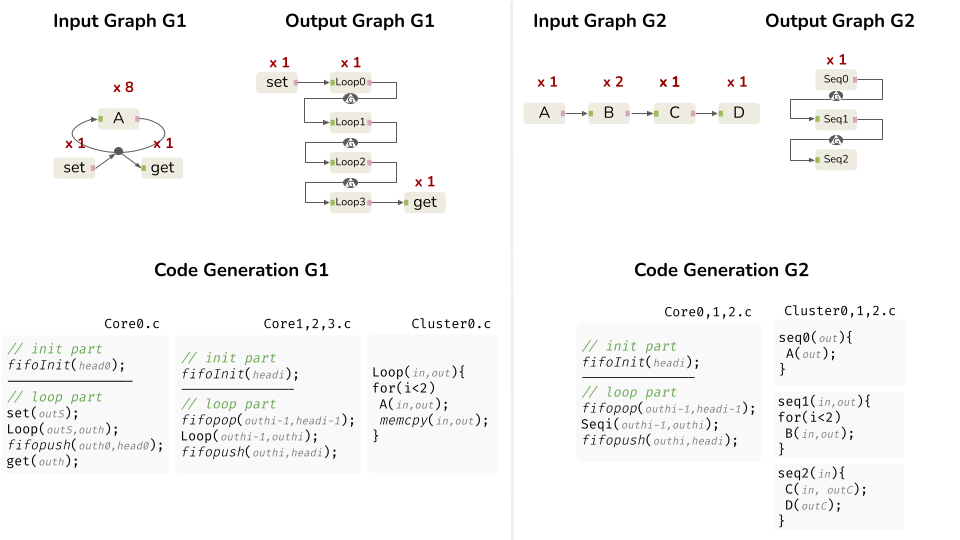
The first version [1] focuses on scaling data parallelism for multi-core CPU architectures with the identification of 2 particular patterns:
- Unique Repetition Count (URC): Sequential actors with identical repetition vector (RV) coefficients, as introduced in [4].
- Single Repetition Vector (SRV): A single actor with an RV exceeding or equal to the number of processing elements (PE) on the architecture.
The subgraph transformation step includes a “scaling” process where identified patterns are clustered into subgraphs, and their repetition is aligned with the target architecture.
This mode reduces the scheduling and placement complexity while maintaining SDF graph parallelism.

Pipeline Parallelism Adjustment
The second version [2] enhances SCAPE by introducing additional patterns for pipeline parallelism:
- Loop Pattern: Sequence of actors where the last is connected to the first by one or more FIFOs with a Local Delay (LD).
- Sequential Pattern: Sequential part of the graph or a part with a degree of parallelism lower than
the number of CPU cores.
The subgraph transformation consist in a “semi-unrolling” process dividing sequential part into time-balanced subgraphs, matching the number of subgraph with the number of CPU cores and pipelining subgraph to match parallelism of the target.
This extension increases parallelism and reduces scheduling complexity but faces challenges with hierarchical graphs containing cycles that disrupt token flow.
Hierarchical Context Awareness
The final extension [3] incorporates hierarchical context awareness to optimize actor clustering while managing cycles in hierarchical graphs. Pattern identification depend on hierarchical levels and actor repetition:
- For repetitions below available PEs: Use URC and SRV patterns, and introduce a new Low-Level Iteration (LLI) pattern for task-level parallelism with minimal performance impact.
- For repetitions exceeding available PEs: Coarse-grained grouping and partial loop unrolling are applied.
This tutorial only demonstrate the first version of SCAPE since the relevance of methods depends on the use case application.
Project Setup
In addition to the default requirements (see Requirements for Running Tutorial Generated Code), please download the following files:
- Complete Sobel-Morpho Preesm Project
- YUV Sequence (7zip) (9 MB)
- DejaVu TTF Font (757KB)
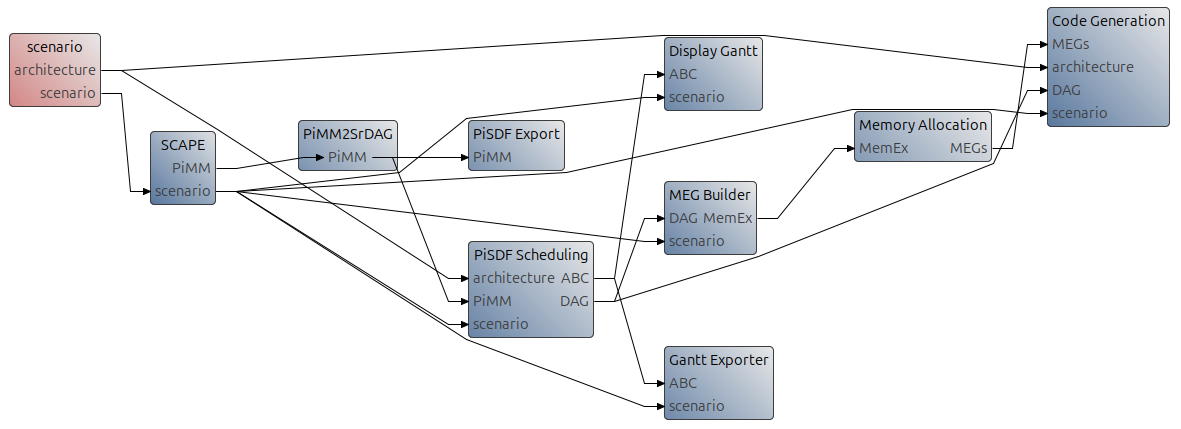
Add the SCAPE process upstream the standard dataflow resource allocation process:
- Open Workflow/ Codegen.workflow.
- Add a new workflow task from the palette.
- Name the task SCAPE.
- Connect it th the scenario, PiMM2SrDAG, Sceduling and Code Generation tasks.
- Click on the task a fill the Basic properties:
| id | SCAPE |
|---|---|
| plugin identifier | scape.task.identifier |
- Click on the task a fill the Task variable properties (more detail, see Workflow Tasks Reference )
| Name | Value |
|---|---|
| Level number | 1 |
| Memory optimization | False |
| SCAPE mode | 0 |
| Stack size | 1048576 |
Launch the resource allocation process:
- Right-click on the workflow “/Workflows/hypervisor.workflow” and select “Preesm > Run Workflow”
- In the scenario selection wizard, select “/Scenarios/initialisation.scenario
During its execution, the workflow will log information into the Console of Preesm. When running a workflow, you should always check this console for warnings and errors (or any other useful information).
Additionnaly, the workflow execution generates intermediary dataflow graphs that can be found in the /Algo/generated/ directory. The C code generated by the workflow is contained in the /Code/generated/ directory.
The resulting Gantt may involve firings of the cluster actor “urc_*” without any mention to Read_YUV, Sobel, Dilation or Erosion.
