Advanced Memory Footprint Reduction
The following topics are covered in this tutorial:
- Memory scripts to customize the memory allocation of actor ports
- Dataflow ports annotation
- Performance optimization by removing useless memory operations
Prerequisite:
- Memory Footprint Reduction Tutorial
Tutorial created the 07.29.2014 by K. Desnos
Project setup
The starting point of this tutorial is the Preesm project obtained as a result of the Memory Footprint Reduction tutorial.
Advanced Memory Optimization
In the optimization technique presented in the Memory Footprint Reduction tutorial, it is assumed that an actor keeps access to all its input and output buffers during its firings. From the memory allocation perspective, this assumption implies that input and output buffers of an actor must always be allocated in non-overlapping memory spaces. The purpose of the techniques presented in this tutorial is to relax this constraint by allowing Preesm to allocate input and output buffers of certain actors in overlapping memory range.
An example of actor whose input and output buffers can be allocated in overlapping memory spaces is the Split actor from the Sobel application. As illustrated in the following figure, the purpose of this actor is to divide the input image into several overlapping slices. Using the memory allocation technique presented in the Memory Footprint Reduction tutorial, the input and output buffers of the Split actor would be allocated in distinct memory spaces. With an input image of 8x9 pixels, 72+120=192 bytes of memory would thus be necessary for the allocation of the input and output buffers.
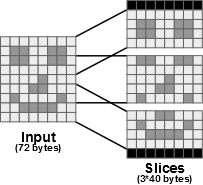
Since each slice produced by the Split actor corresponds to a part of the input image, allowing the allocation of the slices directly within the corresponding part of the input buffer would greatly decrease the memory needed for their allocation. With an input image of 8x9 pixels, only 88 bytes would be allocated for the merged input and output buffers: the 72 bytes of the input buffer and 8 bytes for two additional lines of pixels created by the Split actor.
To allow memory reuse between input and output buffers of actors, new information must be provided to Preesm about the internal behavior of actors and how they access the data contained in their input and output buffer. This new information is provided by two new inputs defined by application developers: Memory Scripts and Dataflow Ports Annotations.
Memory Scripts
A memory script is a small program associated to an actor of a dataflow graph. Contrary to the source code describing the functional behavior of an actor, the only purpose of a memory script is to match ranges of bytes of input and output buffers that can be allocated in a common memory space.
Through the example of the Sobel application and its Split actor, the following sections explain how to create, write and execute a new memory script.
Associate a New Memory Script to an Actor
To create a new memory script and associate it to the Split actor, follow these steps:
- Create a subdirectory “/Code/Scripts”.
- Right-click on the new “Scripts” directory, and select “New->File”.
- Name the new file “split.bsh”
- Double-click on “/Algo/top_display.diagram” to open the graph editor.
- Select the “Split” actor in the editor.
- In the Properties view, click the “Edit” button in the “Memory script” section.
- In the wizard, select the “split.bsh” file and click OK.
- Save “top_display.diagram”.
Scripting Syntax
The language used to for the implementation of the memory script is the BeanShell scripting language [1]. The syntax of the BeanShell language is based on the Java programming language, and supports most of its features (including object programming). In addition to the Java syntax, BeanShell also supports advanced scripting features such as untyped variables. For more information about BeanShell, go to [1].
In Preesm, the memory script associated to an actor of the application graph is executed once for each firing of this actor (i.e. once for each instance of this actor in the single-rate graph). The inputs of a memory script are similar to those provided for the execution of the corresponding actors:
| Symbol | Type | Description |
|---|---|---|
| i_<input_port_name> | Buffer | Buffer associated to an input port of the actor. |
| o_<output_port_name> | Buffer | Buffer associated to an output port of the actor. |
| inputs | List<Buffer> | List containing all buffers associated to the input ports of the actor. |
| outputs | List<Buffer> | List containing all buffers associated to the output ports of the actor. |
| <parameter_name> | Integer | Integer value associated to the parameter for this instance of the actor. |
| parameters | List<Integer> | List of all integer values associated to the parameters of the actor. |
The Buffer class is used in memory scripts to represents the bytes associated to the input and output ports of the actor. The following methods can be used in memory scripts to access the attributes of a buffer:
- String getName(): returns the name of the port, without the ‘i_’ or ‘o_’ prefix of the symbol.
- int getNbTokens(): returns the production or consumption rate of the associated port.
- int getTokenSize(): returns the size of a token in bytes.
- String toString(): returns a String:
<vertexName>.<portName>[<sizeInBytes>].
Finally, two methods can be used to match ranges of bytes of two buffers b1 and b2:
- b1.matchWith(localStart, b2, remoteStart, matchLength)
- Buffer b1: “local” buffer involved in the match.
- int localStart: start index in the local buffer (in tokens).
- Buffer b2: “remote” buffer involved in the match.
- int remoteStart: start index in the remote buffer (in tokens).
- int matchLength: Number of tokens involved in the match.
- b1.byteMatchWith(localStart, b2, remoteStart, matchLength)
- Buffer b1: “local” buffer involved in the match.
- int localStart: start index in the local buffer (in bytes).
- Buffer b2: “remote” buffer involved in the match.
- int remoteStart: start index in the remote buffer (in bytes).
- int matchLength: Number of bytes involved in the match.
In the first methods, the data type of the tokens of the two buffers must be identical (b1.getTokenSize() == b2.getTokenSize()), and all indexes and lengths are expressed as a number of tokens. In the second method, the two buffers can have different types since all indexes and lengths are expressed as a number of bytes.
Write a Memory Script
The following code presents the memory script associated to the Split actor. Copy-paste this code into the “/Code/Scripts/split.bsh” file. The corresponding file can also be downloaded [here].
/**
* Split memory script
* Input buffer: i_input
* Output buffer: o_output
* Parameters: height, width, nbSlice
*/
int sliceSize = width*(height/nbSlice+2);
for(int i=0; i<nbSlice ;i++){
o_output.matchWith( i*sliceSize,
i_input,
(i*height/nbSlice-1)*width,
sliceSize);
}
When executed, this code creates a match for each output slice produced by the Split actor. The following figure illustrates the matches created by this script for parameters height=9, width=8, and nbSlice=3.
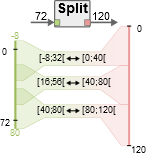
Each output range corresponding to a slice is matched in the corresponding range of the input buffer, thus creating overlaps between the matched input ranges. It is interesting to note that the first and the last ranges of the output buffer are partially matched outside the boundaries of the input byte range [0, 72[. The bytes within the [0, nbTokens*tokenSize[ range of a buffer are called “real” bytes, and bytes outside this range are called “virtual” bytes.
Script Rules
When writing a new memory script, the following rules must be respected:
- A match can be created only between an input and an output buffer. It is strictly forbidden to match an input with another input or an output with another output.
- A range of byte of an output buffer can not be matched several times by overlapping matches.
- All matched ranges must involve at least one byte in the real bytes range.
- Bytes from the virtual bytes range of a buffer can be matched only within the real bytes range of the remote buffer.
If one of these conditions is not met, an error message will be displayed in the console during the script execution.
Configure the Workflow and Execute the Scripts
A new workflow task must be added to the workflow in order to execute the memory scripts of an application. To do so:
- Double-click on “/Workflows/Codegen.workflow” to open the workflow editor.
- Click on “Task” in the palette (on the right side of the workflow editor), then click in the workflow to add a new Task.
- In the “New Vertex” wizard, name the new task “MemoryScripts”.
- Select the new task in the editor and open the “Properties” view.
- In the “Basic” Tab, set the “plugin identifier” property to “org.ietr.preesm.memory.script.MemoryScriptTask”.
- Save the workflow before opening the “Task Variables” tab of the “Properties” of the new task.
- Set the “Check” property to “Thorough”. When learning how to write new memory scripts, the “Thorough” error checking will generate error messages with a detailed description of the source of the error. Once you feel more comfortable with memory scripts, you can set this property to “Fast”. In the “Fast” mode, all errors are still detected, but the generated error messages are less informative. Finally, this property can be set to “None” once all memory scripts have been validated in order to speed-up the workflow execution.
- Set the “Data alignment” property to “None”. The data alignment property should always have the same value as the one set in the properties of the “Mem Alloc” task. (cf. Cache Activation section of the Code Generation for Multicore DSP tutorial).
- Leave the “Log Path” value unchanged. The path given in this property is relative to the “Code generation directory” defined in the executed scenario. If this property is left empty, no log will be generated.
- Set the “Verbose” property to “True”.
- Copy the connection of the following figure in your workflow.
- Save and run the workflow on the 4core.scenario.
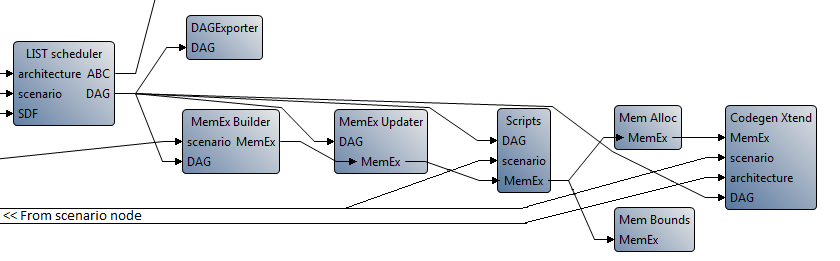
As a result of the workflow execution, the following lines should appear in the “Console”:
16:06:04 Workflow Step: Running Memory Optimization Scripts.
16:06:04 Scripts with alignment:=-1.
16:06:04 Running 3 memory scripts
16:06:04 Checking results of memory scripts with checking policy: Thorough.
16:06:04 Processing memory script results.
16:06:04 Updating memory exclusion graph.
As you will notice, although a unique memory script was assigned in the dataflow graph, 3 memory scripts were executed during the workflow execution. Indeed, the explode and implode actors added during the single-rate transformation are automatically associated to memory scripts. Similarly, the Broadcast and Roundbuffer actors added during the hierarchy flattening of an IBSDF graph are automatically associated to memory scripts. The code of these memory scripts can be downloaded [here].
Open the log generated in “/Code/generated/log_memoryScripts.txt”. For a better readability, we strongly advise you to open this log with a Markdown viewer such as [this one]. The first four lines of this log summarize the result produced by the “Script” workflow task.
# Memory scripts summary
- Independent match trees : 2
- Total number of buffers in these trees: From 19 to 3 buffers.
- Total size of these buffers: From 530112 to 316096 (40.37%).
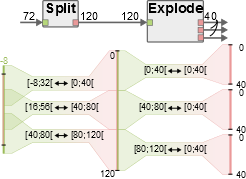
An independent match tree is a chain of buffers and matches formed by the execution of memory scripts associated to actors linked by FIFOs. In the Sobel application, two independent match trees were created. The first one, illustrated in the next figure, is formed by the buffers of the Split and Explode actors, and the second one is formed by the buffers of the Implode actor.
The next two lines of the log give the number of independent buffers, and the total size of these buffers before and after the matches were applied. The following section of the log detail the optimization process for each independent tree. For each tree, the log contains:
- The list of buffers belonging to this tree.
- The step-by-step order in which the matches were applied (cf. [2] for more information).
- The summary of the optimization process for this independent match tree.
- The list of matches that were not applied for this independent match tree (if any).
Problematical Matching Patterns
Matching overlapping ranges in input buffers.
As presented in the generated log, none of the match of the Split actor were applied during the workflow execution. As illustrated in the Split-Explode match trees, the matches created by the Split memory script have overlapping ranges of bytes in the input buffer. If these matches are applied, each output buffer of the explode actor will be merged directly within the input buffer of the Split actor. Consequently, each instance of the Sobel actor connected to an output port of the Explode actor will have a direct access to a part of the input buffer of the Split actor. Since several instances of the Sobel actor can access the same memory space, if one of the instances of the Sobel actor overwrites the bytes contained in its input buffer, it may corrupt the input of other instances. To avoid this issue, matches with overlapping input buffers are not applied unless read_only port annotations, presented in the next section, are used.
Matching overlapping ranges in output buffers.
As presented in the rules above, it is strictly forbidden to overlap the matched ranges of bytes on the output side of an actor as it would systematically corrupt the behavior of an application. The next figure presents an illustration of this issue.
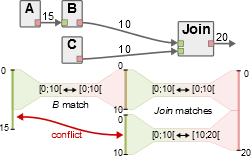
A chain of matches cannot be applied if it results in merging several ranges of bytes in overlapping ranges of an output buffer. In the figure, if all matches were applied, the output buffers of actors A and C would be merged in range [0; 15[ and [10; 20[ respectively of the output buffer of the Join actor. Hence, if all matches were applied actor A and C would access overlapping memory spaces on their output port. In such a case, if actor A was scheduled after actor C, then actor A would partially overwrite the data tokens already produced by actor C, thus corrupting the application behavior. Contrary to matches with overlapping ranges in input buffers, no port annotation can be used to relax this constraint.
Port Annotations
Read_only, Write_only, and Unused Annotations
In the dataflow graph, annotations can be associated to the ports of an actor to specify how this actor will access data on this port. 3 annotations can be used:
- read_only: The actor possessing a read_only input port can only read data from this port. Like a “const” variable in C or a “final” variable in Java, the content of a buffer associated to a read_only port can not be modified during the computation of the actor to which it belongs. The main purpose of the read_only annotation is to allow several buffers to be matched and merged in overlapping ranges of an input port.
- write_only: The actor possessing a write_only output port can only write data on this port. During its execution, an actor with a write-only buffer is not allowed to read data from this buffer, even if data in the buffer was written by the actor itself.
- unused: The actor possessing an unused input port will never write nor read data from this port. Like the “/dev/null device” file in Unix operating systems, an unused input port can be used as a sink to consume and immediately discard data tokens produced by another actor. If a FIFO is connected to a write_only output port and an unused input port, the memory associated to this FIFO can be overwritten even during the execution of its producer or consumers. This property is used in Preesm to reduce the memory footprint allocated to applications.
It is important to note that if the application of a match created by a memory script results in merging an input buffer into an output buffer written by the actor, then the input buffer should not be marked as read_only. This condition holds even if all write operations are performed in ranges of the output buffer that fall outside the ranges merged with the input buffer. For example, the input port of the Split actor cannot be marked as read_only because it is matched in an output buffer whose first and last lines of pixel will be written by the Split actor.
Associate an Annotation to a Port
The following steps explain how to assign the “read_only” annotation to the input port of the Sobel actor.
- Double-click on “/Algo/top_display.diagram” to open the graph editor.
- In the graph editor, select the input port of the FIFO connecting actors Split and Sobel.
- Open the “Properties” view.
- In the “Memory Annotation” property, select “READ_ONLY”.
- Do the same for the output port of the FIFO connecting actors Split and Sobel.
- Save and close the graph.
- Run the workflow on the 4core.scenario.
Once the workflow completes its execution, open the log of the memory scripts. Now that the read_only annotation is associated to the input port of the Sobel actor, all matches created by the memory script were applied by the optimization process. As a result, only 2 buffers remain after the optimization process for a total of 209088 bytes.
The next section presents the positive impact of this memory optimization process on the performance of the application as well as code modifications to apply before compiling and running the generated code.
Impact on Application
Impact on Generated Code
The code generated by Preesm after the application of memory scripts is optimized to increase the application performance. In particular, the code generated for the “special” actors (explode, implode, Broadcast, and Roundbuffer) added during graph transformations is optimized to remove the unnecessary memcpy calls.
For example, the code generated for the implode_Merge_input actor should look like this:
// Join implode_Merge_input
{
memcpy(output__input__1+0, output__input_0__0+0, 13376*sizeof(uchar));
memcpy(output__input__1+13376, output__input_13376__0+0, 13376*sizeof(uchar));
memcpy(output__input__1+26752, output__input_26752__0+0, 13376*sizeof(uchar));
memcpy(output__input__1+40128, output__input_40128__0+0, 13376*sizeof(uchar));
memcpy(output__input__1+53504, output__input_53504__0+0, 13376*sizeof(uchar));
memcpy(output__input__1+66880, output__input_66880__0+0, 13376*sizeof(uchar));
memcpy(output__input__1+80256, output__input_80256__0+0, 13376*sizeof(uchar));
memcpy(output__input__1+93632, output__input_93632__0+0, 13376*sizeof(uchar));
}
When the matches created by the memory scripts are applied, the generated code becomes:
// Join implode_Merge_input
{
}
As a result of the memory script execution, all input buffers of the implode actors have been merged directly within the output buffer. Hence, copying the data from input buffers to the output buffer becomes unnecessary, and the memcpy calls can be removed during the code generation.
Divided Buffers Replaced With Null Pointers
When the matches of the Split actor are applied, the buffer corresponding to the output port of this actor is divided into several parts that are merged separately into the input buffer. In such a case, the memory space corresponding to the output port of the Split actor consists of a non-contiguous memory space that can no longer be accessed with a regular pointer. If the “Verbose” property of the “Scripts” workflow task is set to “True”, the following log entry will appear in the console during the workflow execution:
XX:XX:XX Buffer explode_Split_output.input[107008] was divided and will be replaced by a NULL pointer in the generated code.
A buffer can be divided and matched into non-contiguous ranges of bytes if an only if all actors accessing this buffer expect this division. An actor expects a buffer to be divided if it is associated to a memory script that matches several ranges of bytes of a buffer into non-contiguous remote ranges. In the sobel application, the buffer corresponding to the FIFO between the Split and explode actor fulfill this requirement. Additional requirements for a buffer to be divisible are presented in [2].
To ensure the correct behavior of the application, the C code of the Split actor should be changed as follows (null check on the output and specific behavior in case of split):
void split(int nbSlice, int width, int height, unsigned char *input, unsigned char *output){
if(output != NULL){
int i,j;
int sliceSize = width*height/nbSlice;
// Fill first and last line with 0
memset(output,0,width);
// First Slice
memcpy(output+width, input, sliceSize);
// Copy next line if several slice
if (nbSlice > 1){
memcpy(output + width + sliceSize , input + sliceSize, width);
}
// Slice other than first and last
for(i=1; i<nbSlice-1; i++){
int destIndex = i*(sliceSize+2*width);
memcpy(output + destIndex, input+i*sliceSize-width, sliceSize+2*width);
}
// Last Slice
i = nbSlice-1;
if(nbSlice > 1){
// we have i = nbSlice -1;
int destIndex = i*(sliceSize+2*width);
memcpy(output + destIndex, input+i*sliceSize-width, sliceSize+width);
}
// Last line
memset(output + (height+nbSlice*2-1)*width,0,width);
} else {
// Output has been splitted and is null
// Fill first and last line with 0
memset(input - width, 0, width);
// Last line
memset(input + height*width,0,width);
}
}
Like the explode and implode actors, most of the memcpy calls of the Split actor can be removed when the memory script optimization is used.
Impact on Memory Footprint and Application Performance
On the sobel application, the application of the memory script reduces the memory footprint allocated to the application by 20%, in addition to the 32% reduction obtained when applying techniques presented in the Memory Footprint Reduction tutorial. Overall, the techniques presented in these two tutorials helped reduce the memory footprint by 62% compared to the basic allocation, from 666kBytes to 254kBytes. On larger applications, such as the one presented in [3], a reduction of the memory footprint by up to 95% were observed.
On a 4core CPU, the application of memory scripts also leads to an increase of the Sobel application throughput by 5%. On larger applications, such as the one presented in [3], increase of the throughput by up to 90% were observed.
References
[1] BeanShell WebPage - http://www.beanshell.org/intro.html
[2] K. Desnos, “Memory Study and Dataflow Representations for Rapid Prototyping of Signal Processing Applications on MPSoCs”, PhD Thesis, 2014. (PDF)
[3] K. Desnos, M. Pelcat, J.-F. Nezan, S. Aridhi, “Memory Analysis and Optimized Allocation of Dataflow Applications on Shared-Memory MPSoCs”, Journal of Signal Processing Systems (JSPS), Springer, 2014. (link)