Reconfigurable Application with SPIDER - [BETA]
Writing of this tutorial is currently in progress. If you wish to follow this tutorial, please consider yourself as a beta tester (and don’t hesitate to send us any improvement suggestions).
The following topics are covered in this tutorial:
- Spider’s operating principle
- Retrieving a compiled version of the Spider library
- Modification the Sobel filter example to add reconfigurability.
- C Code generation for Spider using Preesm.
- Compiling the Sobel filter with the Spider library
Prerequisite:
Tutorial created the 11.07.2017 by H. Miomandre
Project setup
In addition to the default requirements (see Requirements for Running Tutorial Generated Code), download the following files:
- Complete Sobel Preesm Project
- YUV Sequence (7zip) (9 MB)
- DejaVu TTF Font (757KB)
About reconfigurability
All applications developed and optimized in previous tutorials, where modeled with “static” dataflow graphs. A graph is said to be static when the numbers of data tokens consumed and produced by an actor at each firing are defined with expressions whose integer values can be computed at compile time. This static property enforces the predictability of the dataflow model, and paves the way for powerful optimizations of the applications during the compilation process, like those presented in the memory optimization tutorials.
Although the static property is a strong asset for compile-time optimizations, this property limits the range of application behaviors that can be modeled. For example, a static graph can not be used to model an algorithm where the execution of some actors may be enabled or disabled at runtime, depending on the value of a data token produced by a sensor. A concrete algorithm with such a behavior is a facial expression recognition algorithm with a first set of actors responsible for locating a face in a picture, and a second set of actors responsible for recognizing its expression. In this example, if no face has been located in a picture by the first set of actors, it is useless to try to recognize a facial expression in this frame, and the second set of actors should be disabled.
The purpose of this tutorial is to show how a reconfigurable behavior can be modeled with the dataflow graph editor of Preesm, by specifying special actors, called configuration actors, that may set new values for parameters of the graph at runtime.
Details on the semantics and mechanisms of the PiSDF reconfigurable dataflow model of computation implemented in Preesm are available in [1].
Spider presentation
Spider Runtime Objectives
Setting a new value for a parameter of a graph at runtime has a strong impact on how actors of this graph will be executed. For example, increasing the value of a parameter used as a production rate by an actor will have an impact on the amount of memory allocated for the output buffer of this actor. By changing consumption and production rates of actors dynamically, the number of execution of these actors may be modified, thus requiring a new mapping of these executions on the processing elements of the architecture.
In order to support these runtime reconfigurations of the graph parameters, a special process, called a runtime, is needed to manage their impact on the graph and deploy dynamically the application on the targeted architecture. The runtime can be seen as a small operating system acting as an adaptation layer between the reconfigurable dataflow graph, and the resources (processing elements, memory, means of communication, …) of the targeted architecture.
The runtime responsible for managing reconfigurable dataflow graph modeled in Preesm is called Spider which stands for Synchronous Parameterized and Interfaced Dataflow Embedded Runtime.
Structure of Spider
The Spider runtime software architecture is separated into several layers. Those layers make the runtime independent from both the application and the platform on which it runs.
Layers are separated as followed:

- Application Layer : The application layer is application specific, it is composed of actor sources (written in C/C++) and the PiSDF graph that models the application. The PiSDF graph can be either generated with handwritten code or using a code generator embedded in Preesm framework.
- Runtime Layer : The runtime layer is the core of the Spider runtime, it is composed of two parts, the master part called Global RunTime (GRT) and the slave parts called Local RunTime (LRT). The master part is used to schedule the application on the several slave parts that execute the different actors.
- Hardware Specific Layer : The hardware specific layer, also called Platform layer, is the part that handle the inter-core communication and synchronization. It is platform specific and designed to fully exploit the platform specificities to reach maximum performance.
Execution Scheme
The typical execution scheme of the Spider runtime is expressed as followed:

- Schedule Actors: The GRT schedule the application’s actors onto the several cores available on the platform.
- Send Order: Then the GRT sends orders in the Jobs Queues. A Job is a data structure that allows an LRT to execute a specific actor. It includes, but is not limited to, which actor function to execute and with which data.
- Fire Actors: LRTs execute the actors code.
- Exchange Dataflow Tokens: LRTs post and retrieve data tokens from Data queues.
- Set Resolved Parameters: When a configuration actor is executed, parameter values may be resolved, then LRTs send this result to the GRT.
- Execution Traces: Execution trace are sent into the Timings Queues to give feedback on the current execution, it allows the Spider runtime to print a Gantt chart of past executions. When using the Papify automatic instrumentation, the instrumented measured are written to specific files (See Papify Instrumentation).
The Spider runtime is currently compatible with x86 and ARM architectures (Windows, Linux), Keystone II architectures from Texas Instruments, and the MPPA256 many-core processor from Kalray. More information on Spider is available in [2].
Spider library
The Spider runtime is provided as a library when building a dynamically reconfigurable application. See Building Spider to build it on your machine.
Modification of the Sobel algorithm
We need to modify the current Sobel algorithm to add a configuration actor and make the graph reconfigurable.
Prepare the project
It is important to note that the project resulting from this tutorial will no longer be compatible with the workflows used in tutorials 1 to 7. Hence, we strongly advise you to back up your current Sobel project.
If “/Code/generated/” is not empty, delete its content. Also change the extension of every .c file in “/Code/src/” to .cpp.
Update algorithm model
Download the following archive [link] which contains:
- the code of a configuration actor that you’re about to add in Preesm,
- an additional file that might be needed if you compile your program with Visual Studio.
The next steps will add a configuration actor in our Sobel algorithm graph to make it a reconfigurable.
- Copy-paste the “nbSliceSetter.cpp” and “nbSliceSetter.h” files from the archive into “/Code/src/” and “/Code/include/”, respectively.
- In Preesm, refresh the package explorer (either by pressing [F5], or with a right-click > “Refresh”)
- In the graph editor of Preesm, create a new actor and name it “nbSliceSetter”
- Right-click on the new actor and select “Add new configuration output port”, name it “nbSlice”.
- Select “Dependency” in the left-hand palette of the graph editor, and connect the “nbSlice” configuration output port to the nbSlice parameter.
- Using the procedure presented in previous tutorials, set “nbSliceSetter.h” as the refinement for the configuration actor.
- The
heightparameter input of the configuration actor is used for initializing the value ofnbSlicewhen the application starts.
The resulting graph should look like this:
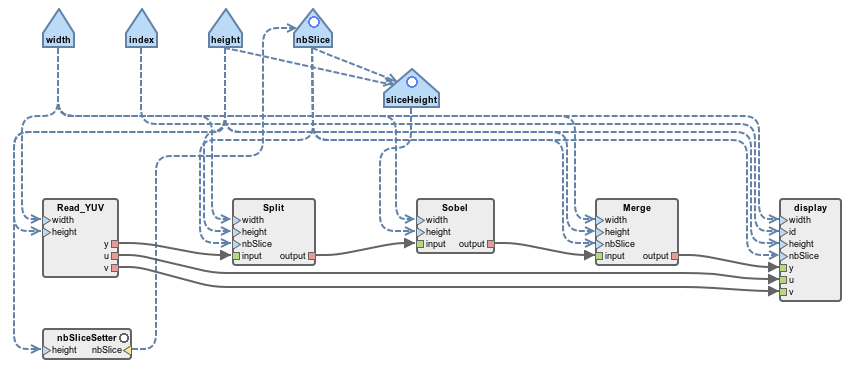
The white dots that appear on the nbSliceSetter actor, and on the nbSlice and sliceHeight parameters show that these graph elements constitute a reconfigurable part of the graph. It should be noted that a configuration actor changing the value of a parameter can not receive data tokens from another actor of its graph. As detailed in [1], hierarchy levels must be used to allow a configuration actor to consume data tokens.
At this step, you must update the mapping constraints specified in the scenario to allow the execution of the newly created configuration actor on at least 1 core.
Create a Spider workflow
We now need to tell Preesm to use the Spider codegen instead of the C code generation used in previous tutorials.
- Right-click in the “Package Explorer” and select “New > Other”. In the opened wizard, select “Preesm > Preesm Workflow” to create a new workflow in the “/Workflows/” directory and name it “SpiderCodegen.workflow”.
- Add a “Scenario” source bloc from the Workflow editor Palette with:
- id : “scenario”
- plugin identifier : “org.ietr.preesm.scenario.task”
- Add a “Task” bloc with:
- id : “Spider Codegen”
- plugin identifier : “org.ietr.preesm.pimm.algorithm.spider.codegen.SpiderCodegenTask”
- Link them with three “Data transfer” connections:
- “scenario”
- “architecture”
- “PiMM”
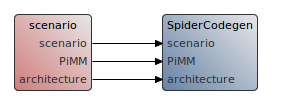
Once it’s done, you can start the codegen by running the workflow with the 4 cores scenario.
Sobel filter with Spider
Update the CMake
We need to change the CMake behavior to have it look for and link the Spider library.
- (1) Copy “FindSpider.cmake” from the provided archive into “/Code/lib/cmake_modules/”
- (2) Open “/Code/CMakeLists.txt” and insert the following text AFTER the pthread section:
# *******************************************
# ************ Spider LIBRARY ***************
# *******************************************
# find the spider folder in the libspider directory.
file(GLOB SPIDERDIR "${LIBS_DIR}/spider")
set(ENV{SPIDERDIR} ${SPIDERDIR})
Find_Package (Spider REQUIRED )
if(NOT SPIDER_FOUND)
MESSAGE(FATAL_ERROR "SPIDER not found !")
endif()
if (WIN32)
file(GLOB
SPIDER_DLL
${SPIDERDIR}/lib/*.dll
)
MESSAGE("Copy SPIDER DLLs into ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}")
if(NOT ${CMAKE_GENERATOR} MATCHES "Visual Studio.*")
file(COPY ${SPIDER_DLL} DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY})
else()
file(COPY ${SPIDER_DLL} DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/Debug)
file(COPY ${SPIDER_DLL} DESTINATION ${CMAKE_RUNTIME_OUTPUT_DIRECTORY}/Release)
endif()
endif()
- (3) At the end of the CMakeLists.txt file, add ${SPIDER_INCLUDE_DIR} as an argument of include_directories()
- (4) In the file() command, change arguments from “.c” to “.cpp” to tell CMake to look for c++ source files instead of c source files.
- (5) In the file() command, add “./generated/*.h” as an argument.
- (6) Add ${SPIDER_LIBRARY} as an argument of target_link_libraries().
Set up Spider
When it’s done, simply run the updated CMake script to set up the project and compile the program.
Note: CodeBlocks users, make sure you do not use the version of MinGW provided with CodeBlocks installer (4.9.2) as it is shipped with its own outdated, incompatible implementation of PThread. Please install the latest version of MinGW (5.3.0) from the MinGW website [link].
Visual Studio users only: if the executable refuses to start because of a missing MSVCR90.dll or giving a R6034 error, do the following:
- Open Windows Registry Editor (or use this .reg file and go to step 4).
- Go to
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\SideBySide. - Create a DWORD key named “PreferExternalManifest” with value “1”.
- Copy the “sobel_spider.exe.manifest” from the provided archive in the same directory as the compiled program.
- Rename “sobel_spider.exe.manifest” to “<your_program_name>.exe.manifest”.
- Run the program.
The number of core used by Spider to run the application can be changed by modifying the constant “NB_LRT” in “main.cpp”. In the normal Preesm codegen, mapping and scheduling is done by Preesm, and therefore fixed at compile time. With Spider, mapping and scheduling is determined at runtime. It means that if an actor is executable on every core (by the “Constraints” tab), Spider is free to send the corresponding job to the first available core.
CAUTION
Note that LRTs are linked to the architecture described in Preesm. When changing manually the number of LRT in the “main.cpp” you should also make changes in the “<project_name_>archi.cpp” file corresponding to the architecture seen by Spider.
We strongly advise you not to do it manually but to use the spider codegen to avoid any segmentation fault.
Monitoring the Graph Execution with Spider
Spider can provide you with different tools to monitor the execution of your application:
- You can monitor the global timing of your application and Spider overhead time by setting the value of “cfg.traceEnabled” to true in the “main.cpp” file.
This will display the timing in the console and also output a “gantt.pgantt” file that can be viewed using the GanttDisplay. The generated gantt correspond to the gantt of the last complete graph iteration. - You can also monitor individual actors using the automated Papify Instrumentation.
References
[1] Desnos, Karol; Pelcat, Maxime; Nezan, Jean-François; Bhattacharyya, Shuvra S.; Aridhi, Slaheddine (2013) “PiMM: Parameterized and Interfaced Dataflow Meta-Model for MPSoCs Runtime Reconfiguration”. SAMOS XIII, Samos, Greece.
[2] Heulot, Julien; Pelcat, Maxime; Desnos, Karol; Nezan, Jean-François; Aridhi, Slaheddine (2014) “SPIDER: A Synchronous Parameterized and Interfaced Dataflow-Based RTOS for Multicore DSPs”. EDERC 2014, Milan, Italy.